3 - 대용량 데이터 처리의 진화
데이터브릭스 데이터 엔지니어링
“데이터를 모으는 건 시작일 뿐. 진짜 일은 ‘잘 쓰이도록’ 만드는 것이다.”
왜 데이터 엔지니어링이 중요한가?
데이터 분석이 아무리 훌륭해도, 신뢰할 수 없는 데이터, 정제되지 않은 데이터, 제때 도착하지 않는 데이터라면 아무 소용이 없습니다. 결국 모든 분석과 AI는 데이터 파이프라인이라는 기반 위에서 돌아갑니다.
특히 게임, 웹, 앱 같은 빠르게 변화하는 서비스에서는 실시간 사용자 행동 로그, 이벤트 트래킹, 시스템 모니터링 데이터 등을 지속적으로 수집하고, 이를 빠르게 분석 가능하게 만드는 고성능 데이터 처리 체계가 필수입니다.
이 역할을 단단히 뒷받침해주는 것이 바로 데이터브릭스의 데이터 엔지니어링 기능입니다.
핵심 기술 1. Spark 기반 분산 처리 엔진
데이터브릭스는 아파치 스파크(Apache Spark)를 기반으로 설계된 플랫폼입니다. Spark는 대용량 데이터를 수천 개의 노드에 나눠 병렬 처리할 수 있어, 다음과 같은 작업에서 뛰어난 성능을 발휘합니다:
- ✅ 데이터 전처리 (ETL)
- ✅ 로그 집계 및 세션 분석
- ✅ 실시간 스트리밍 처리 (Kafka/Flink 대안)
- ✅ ML 모델 학습을 위한 대규모 데이터셋 가공
Spark는 배치와 스트리밍 처리를 모두 지원하며, PySpark, Spark SQL, Scala 등 다양한 API를 제공합니다. 데이터브릭스는 이러한 Spark 작업을 매우 쉽게 관리할 수 있도록 클러스터 자동 관리 기능과 통합 개발 환경(Notebook)을 제공합니다.
💡 실제로 '리그 오브 레전드'의 로그 분석도 Spark 기반으로 실시간 처리됩니다.
핵심 기술 2. 델타 레이크(Delta Lake) – 데이터 레이크의 신뢰성 강화
기존의 데이터 레이크는 유연하지만 다음과 같은 한계가 있었습니다:
- ❌ 데이터 수정/삭제가 어려움
- ❌ 스키마 불일치로 오류 발생
- ❌ 정합성 보장이 어려움
이를 해결한 것이 데이터브릭스의 오픈소스 기술인 Delta Lake입니다. Delta Lake는 Parquet 같은 기존 포맷 위에 ACID 트랜잭션, 스키마 진화, 타임 트래블(Time Travel) 기능을 추가한 스토리지 계층입니다.
주요 특징:
- 🔄 Update/Delete/Merge 지원 → GDPR 등 데이터 삭제 요구에도 대응
- 🧬 스키마 자동 관리 → 새로 들어온 컬럼도 자동 인식
- ⏳ 버전 관리 → 과거 시점의 테이블 조회 가능 (예: 3일 전 데이터 상태 보기)
- 🔁 배치/스트리밍 통합 → 동일 테이블에 동시에 쓰고 분석 가능
✅ Delta Lake는 “데이터 레이크의 안정성”을 획기적으로 끌어올린 핵심 기술입니다.
핵심 기술 3. Photon 엔진 – 초고속 쿼리 처리
Delta Lake 위에 데이터를 쌓았다면, 그 데이터를 빠르게 쿼리할 수 있어야 하겠죠?
데이터브릭스는 이를 위해 Photon이라는 자체 쿼리 엔진을 제공합니다. Photon은 C++로 개발된 벡터화 실행 엔진으로, 기존 Spark SQL 대비 최대 10배까지 빠른 쿼리 성능을 보여줍니다.
활용 시나리오:
- 📊 대시보드 실시간 쿼리 (BI 툴에서 빠른 응답)
- 🧮 분석가들의 SQL 질의
- 🔁 대용량 데이터 정기 집계 작업
💡 Photon은 특히 반복적인 분석 작업이나, 대량의 조인 연산이 있는 쿼리에 큰 이점을 제공합니다.
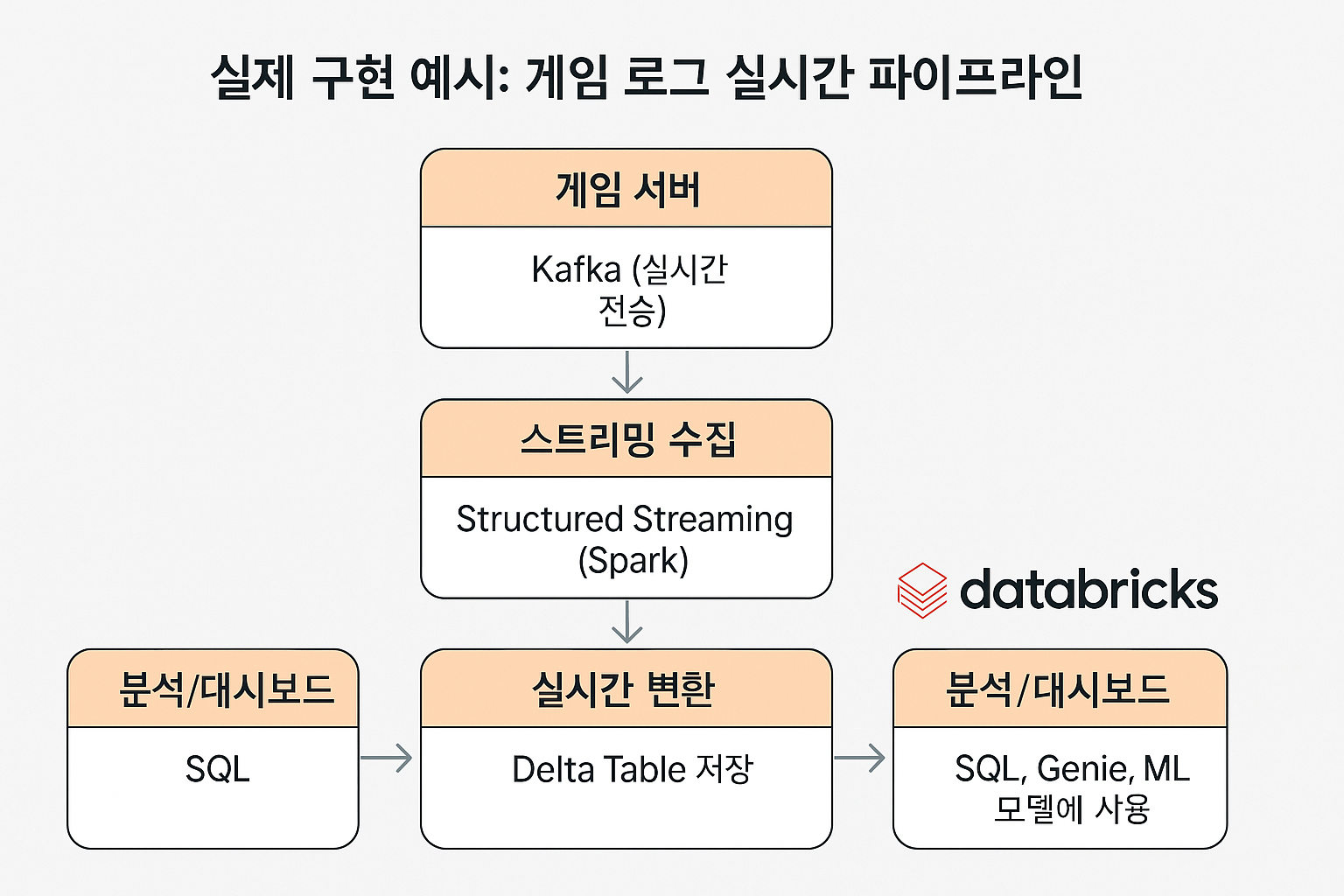
실제 구현 예시: 게임 로그 실시간 파이프라인
[ 게임 서버 ]
↓ Kafka (실시간 전송)
[ 스트리밍 수집 ]
↓ Structured Streaming (Spark)
[ 실시간 변환 ]
↓ Delta Table 저장
[ 분석/대시보드 ]
↓ SQL, Genie, ML 모델에 사용
- 데이터 엔지니어는 Delta Live Tables를 활용해 파이프라인을 자동화
- 분석가는 쌓인 Delta Table을 SQL로 질의하거나 EDA 수행
- PM/비즈니스 사용자는 대시보드를 통해 결과 확인
엔지니어를 위한 추가 기능
기능 설명
| Delta Live Tables (DLT) | 선언적 파이프라인 작성, 자동 오류 복구 및 품질 검증 |
| Jobs | 스케줄 기반 배치 처리 (예: 매일 6시 리포트 생성) |
| Repos | Git 연동을 통한 버전 관리 및 팀 협업 |
| Unity Catalog | 데이터 접근 권한 및 계보 관리 (Lineage Tracking) |
| 자동 클러스터 스케일링 | 처리량에 따라 클러스터 자동 확장/축소로 비용 최적화 |
요약: 데이터가 살아 움직이게 만드는 힘
데이터브릭스의 데이터 엔지니어링은 단순한 ETL 플랫폼을 넘어, **“데이터의 생산 → 정제 → 분석”**까지의 모든 과정을 아우릅니다. 특히 Spark + Delta Lake + Photon 조합은 다음과 같은 가치를 제공합니다:
- 빠르고 유연한 처리: 실시간 & 배치 통합
- 신뢰 가능한 데이터 품질: ACID 보장, 자동 스키마 관리
- 확장성과 경제성: 클라우드 기반 자동 확장, 비용 제어
- 재사용성과 협업: 정의된 파이프라인 재사용 및 팀 기반 협업
다음 편 예고: 이 데이터를 AI가 쓴다면?
정제된 데이터를 쌓았으면, 이제는 그 데이터를 AI와 머신러닝에 활용할 차례입니다. 데이터브릭스는 ML/AI 개발도 하나의 플랫폼 안에서 손쉽게 할 수 있도록 강력한 기능들을 제공합니다.
다음 편에서는 Databricks 노트북, MLflow, AutoML, Feature Store 등 데이터 과학과 MLOps를 위한 기능들을 살펴보겠습니다.
다음 글: 4 - AI/ML 개발의 진화